
Deploying LLaMA-2-7b to a REST API Endpoint for Text Summarization with Modelbit
Large Language Models (LLMs) like Large Language Model Meta AI (or LLaMA 2) are notoriously difficult to deploy to production. Why? For starters, they are “large,” and any software with large components requires multiple facets to manage:
- Memory requirements: LLMs have significant memory requirements—a major bottleneck from a deployment perspective because you would need to provision hardware that ensures your model service does not run out of memory during long-running inference.
- Dependencies: Like any traditional ML deployment, you need a consistent development and deployment environment that is up-to-date and patched for security concerns when you swap or update your LLMs. The versions of the dependencies may get bumped up, but you don’t consider the production dependencies.
- Available accelerators: We’d be kidding ourselves if we want to deploy LLMs and are not considering GPUs, TPUs, or other accelerators if we want fast inference and a good user experience.
- Complex engineering overhead and infrastructure availability: Deploying LLMs, especially in enterprise settings, involves complex engineering overhead, especially when deploying custom models within a secure environment. There are high inferencing costs due to the model's scale, which could lead to a long time-to-value or return on investment.
As you progress through this tutorial, you’ll observe that with two steps—modelbit.login() and mb.deploy(), you will deploy an LLM to a GPU-based (or “GPU-rich” 😉) production environment. Okay, that’s worth repeating—deploy an LLM with two steps! Essentially, these two steps will alleviate all the complex engineering overhead you saw earlier with deploying and managing LLMs as a production service.
This tutorial will teach you how to use LLaMA-2 and LangChain to build a text summarization endpoint that you can deploy as an inference service with Modelbit. By the end of this article, you will:
- Use LangChain to orchestrate the prompts and create templates to generate X (Twitter) thread summaries with the LLaMA 2-7B 🦙 model.
- Deploy a text summarization service built with the model to Modelbit.
Here’s an overview of the solution you will build in this article:
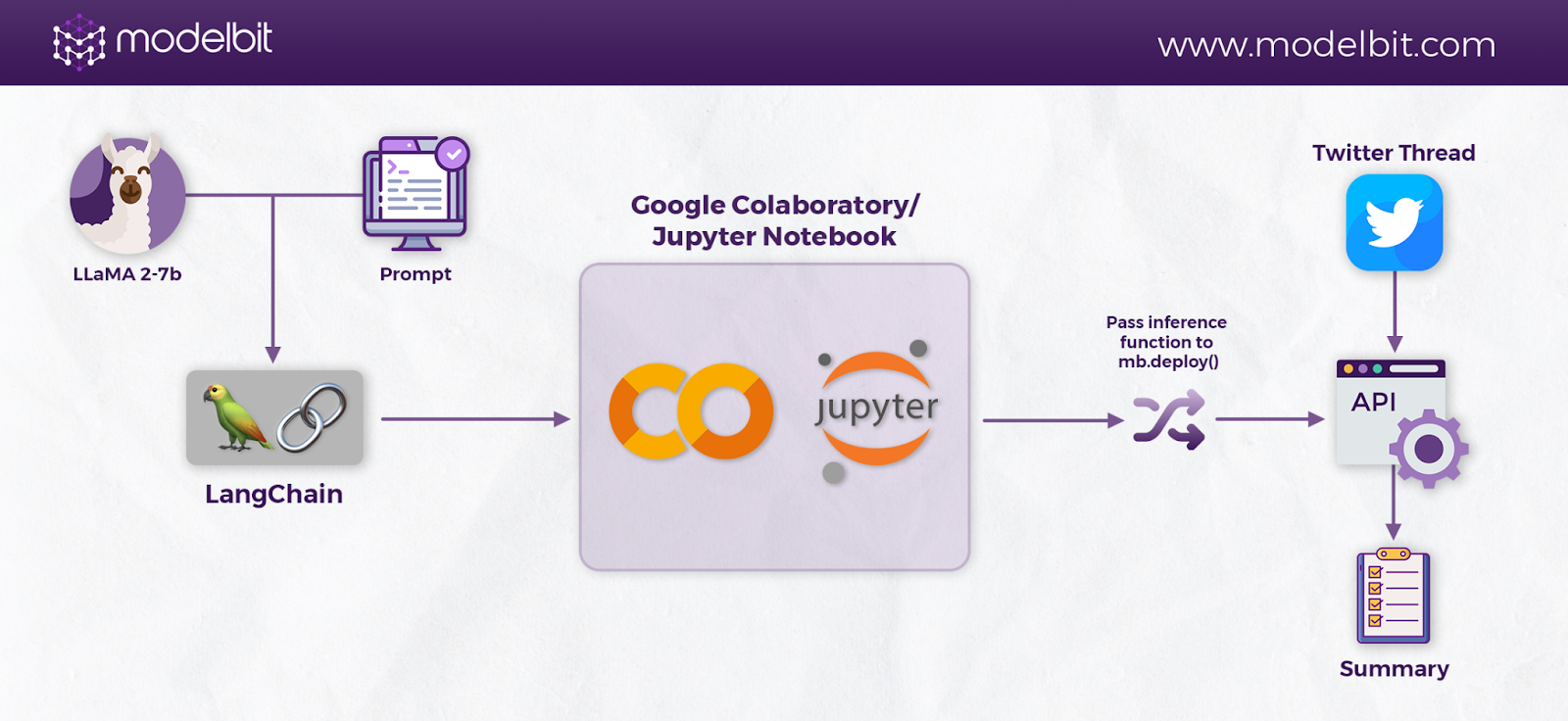
Let’s delve right in! 🚀
LLaMA-2 Model Architecture
LLaMA-2 is a family of Meta's pre-trained and fine-tuned large language models with 7B to 70B parameters. It follows a multi-layer transformer architecture as an open-source collection, incorporating encoder-decoder components based on the classic transformer architecture.
LLaMA-2 is designed to offer a wide range of applications, like:
- Natural language generation - generating text for creative writing, blog posts, marketing copy, stories, poems, novels, and even YouTube scripts or social media posts.
- Machine translation - translating text from one language to another, focusing on English-language use cases.
- Summarization - summarizing different forms of text, ranging from news articles and research papers to video content.
- Code generation - generating or debugging code, which makes it easy for developers to enhance code quality, among other things.
The architecture of LLaMA-2 is better than its closed-source predecessor, LLaMA-1. For example, the context length has been increased from 2048 to 4096 tokens, and grouped-query attention (GQA) has been added. These changes have improved the model's capability for long document understanding, chat histories, and summarization tasks.
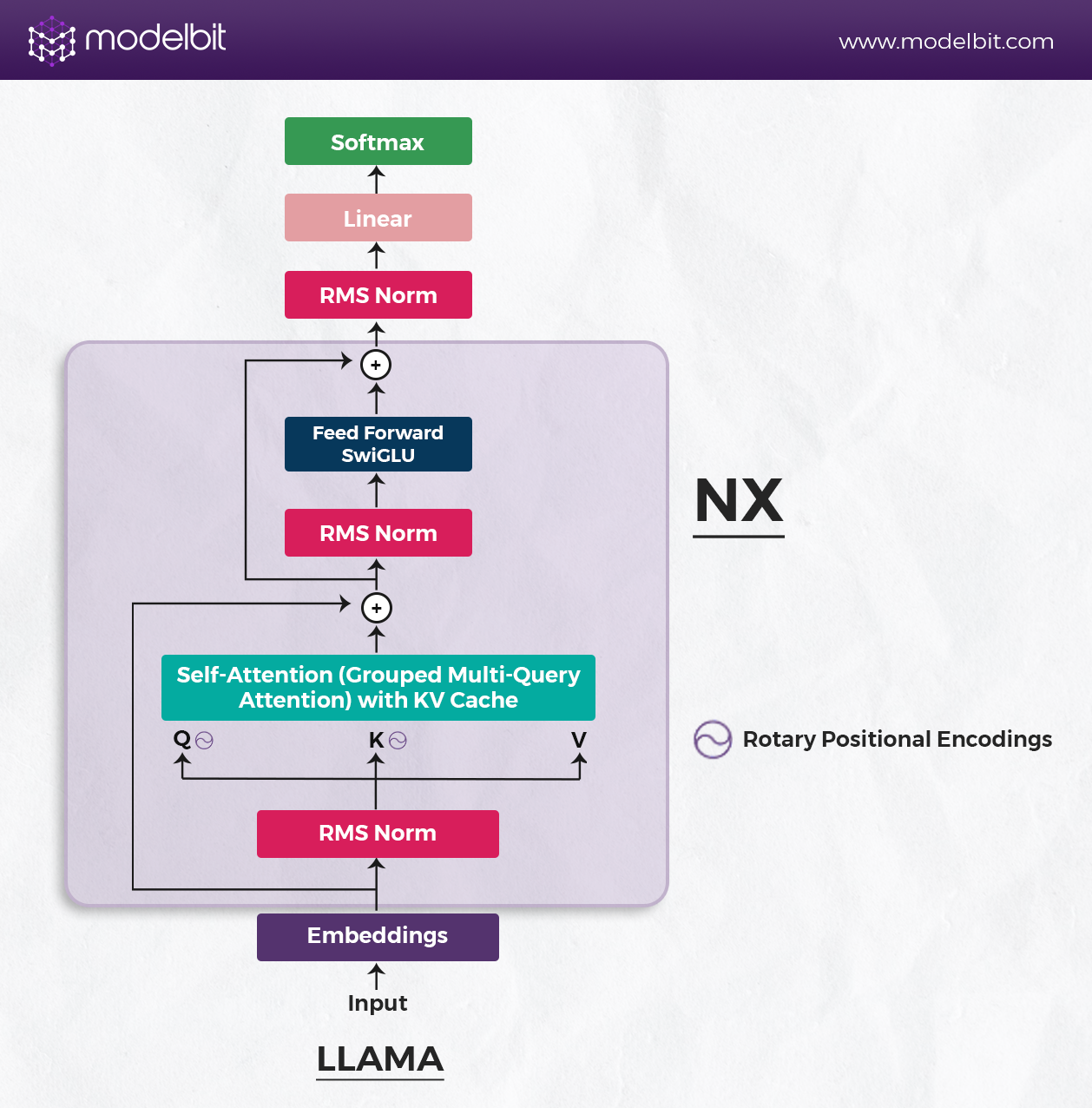
LLaMA-2 components include:
- RMSNorm - for efficiently handling 2 trillion tokens and internal weights.
- SwiGLU activation - to determine neuron activity.
- RoPE (Rotary Positional Embedding) - to recognize the importance of word positions in sentences.
Now that you have understood the additional architectural component in LLaMA-2 that makes it unique from the classical encoder-decoder transformer architecture.
In the next section, you will learn how to build a Twitter thread summarizer service with Langchain and Modelbit.
Prerequisites for Loading and Deploying LLaMA 2-7B 🦙
Deploying LLaMA-2 can be complex because the models have 7B to 70B parameters. However, with the right tools, you can manage the deployment workflow. Running the LLaMA model in half-precision (Float16) requires 14 GB of GPU memory for inference, but with 4-bit algorithms, the memory requirements are significantly reduced. This means you only need about 4 GB for a 7-billion-parameter model.
In full precision (Float32), each parameter is stored in 32 bits, or 4 bytes, requiring 28 GB of GPU memory for a 7 billion parameter model. The memory requirement for 8-bit precision would be less than full precision but more than 4-bit precision.
In this tutorial, you will:
- Load and test LLaMA 2-7b with LangChain and “huggingface_hub” (for downloading “llama.cpp” embedding model)
- Deploy the embedding model as a REST API endpoint to respond to real-time and batch user prompts.
🦜🔗 LangChain
LangChain is an open-source library for building applications powered by large language models (LLMs). With LangChain, you can create LLM-centric applications that cater to specific needs, such as chatbots, virtual assistants, language translation, document summarization, question and answer, and retrieval augmented generation applications.
Its core components include:
- Documents — represent text pieces with metadata
- Models — encompass the language models
- Chat Models and Text Embedding Models
Chains — facilitate the automated combination of various LLM calls and actions.
🟪 Modelbit
Modelbit is a lightweight platform designed to deploy any ML model to a production endpoint from anywhere. Deploying small or large models is as simple as passing an inference function to “modelbit.deploy()”.
Here are the basics you need to know about Modelbit:
- Deploy from any Python environment: Models can be deployed directly from Google Colab (or local Jupyter Notebooks), Hex, Deepnote, VS Code—any Python environment.
- Detect dependencies: Automatically detects which dependencies, libraries, and data your model needs and includes them in your model’s production Docker container.
- Launch a REST API Endpoint: Your model will be callable as a RESTful API endpoint.
- Git-based version control: Track and manage model iterations with Git repositories.
- CI/CD integration: Integrate model updates and deployment into continuous integration and continuous delivery (CI/CD) pipelines like GitHub Actions and GitLab CI/CD.
Installations and Setting Up Your Environment
For this tutorial, we'll use Google Colab. This tutorial assumes you have GPUs enabled when loading LLaMA 2-B to Colab and deploying the model to Modelbit.
Check the Colab Notebook for the entire code.
To set up your environment, install the following packages:
- LangChain - “langchain==0.0.335”
- Modelbit - “modelbit==0.30.13”
- Huggingface_hub - “huggingface-hub==0.19.1”
- LLaMA_cpp_python - “llama_cpp_python==0.2.17”
As of this writing, those are the specific versions the following `pip` command installs:
Next, load the embedding model directly onto your GPU device and install the LLaMACpp Python package. The “LLaMA_cpp_python” package provides Python bindings for the llama.cpp library that bridge the gap between the C++ codebase of Llama and Python to access and use the functionalities of the “llama.cpp” library directly from Python scripts.
Run the following command:
Setting the environment variable “CMAKE_ARGS” with the value “-DLLAMA_CUBLAS=on” indicates that the “llama_cpp_python” package should be built with NVIDIA’s cuBLAS support. “FORCE_CMAKE=1” instructs the installation process of the llama-cpp-python package to use cuBLAS for the build process, even if other build systems are available.
Once that’s complete, install the Hugging Face CLI command, which you will use to obtain the LLaMA-2-7B-GGUF model files from the “TheBloke/Llama-2-7B-GGUF” HuggingFace model repository (there are other torrents you could download from in Hugging Face).
Run the following command:
Set Up the Prompt Template with LangChain
After downloading the model file, set up a prompt template. The prompt template defines the input variables and the response format for the LLaMACpp model.
In this case, the input variables are "text" and "num_of_words," representing the Twitter thread and the desired length of the summary, respectively. The response format is a string that includes the original Twitter thread and the generated summary.
Set up the prompt template by running the following code:
Initialize LLaMA 2-7b Model Weights and LLMChain
After crafting the prompt, set up the model file paths and define a function to initialize the LLaMACpp model with the following:
- Specified model file paths,
- Context size (“n_ctx”),
- Number of GPU layers (“n_gpu_layers”) - to manage GPU memory usage and computational efficiency when Llama 2-7B runs,
- “n_batch=20” (batch size),
- “f16_kv=True” (indicating the use of half-precision for key-value cache)
PS: Play around with those parameters to optimize the balance between performance and resource utilization for the LlamaCpp model.
Here’s the link to the complete Colab Notebook.
Notice the “@cache” decorator? It ensures that the embeddings from “load_llm()” are stored so that subsequent calls with the same arguments don't recompute the function but return the stored embeddings to optimize performance.
Define LLaMA 2-7B Inference Function
Wrap the model in an inference function:
Let’s break down the code snippet:
- This function takes a text string and an optional “num_of_words” argument (defaulting to 200).
- “llm = load_llm()” - calls the “load_llm” function to get the loaded LLaMACpp model.
- “chain = LLMChain(llm=llm, prompt=prompt)” - Instantiates an LLMChain object with the LLaMACpp model and a prompt.
The function executes the LLM chain with the prompt we set up through the prompt template and the LLaMA 2-7B embeddings. It takes the input text for inference (the user query; in this case, a Twitter thread) and a word limit. It should return a summary of the text input.
Test the Inference Function with a Sample Twitter Thread 🧵
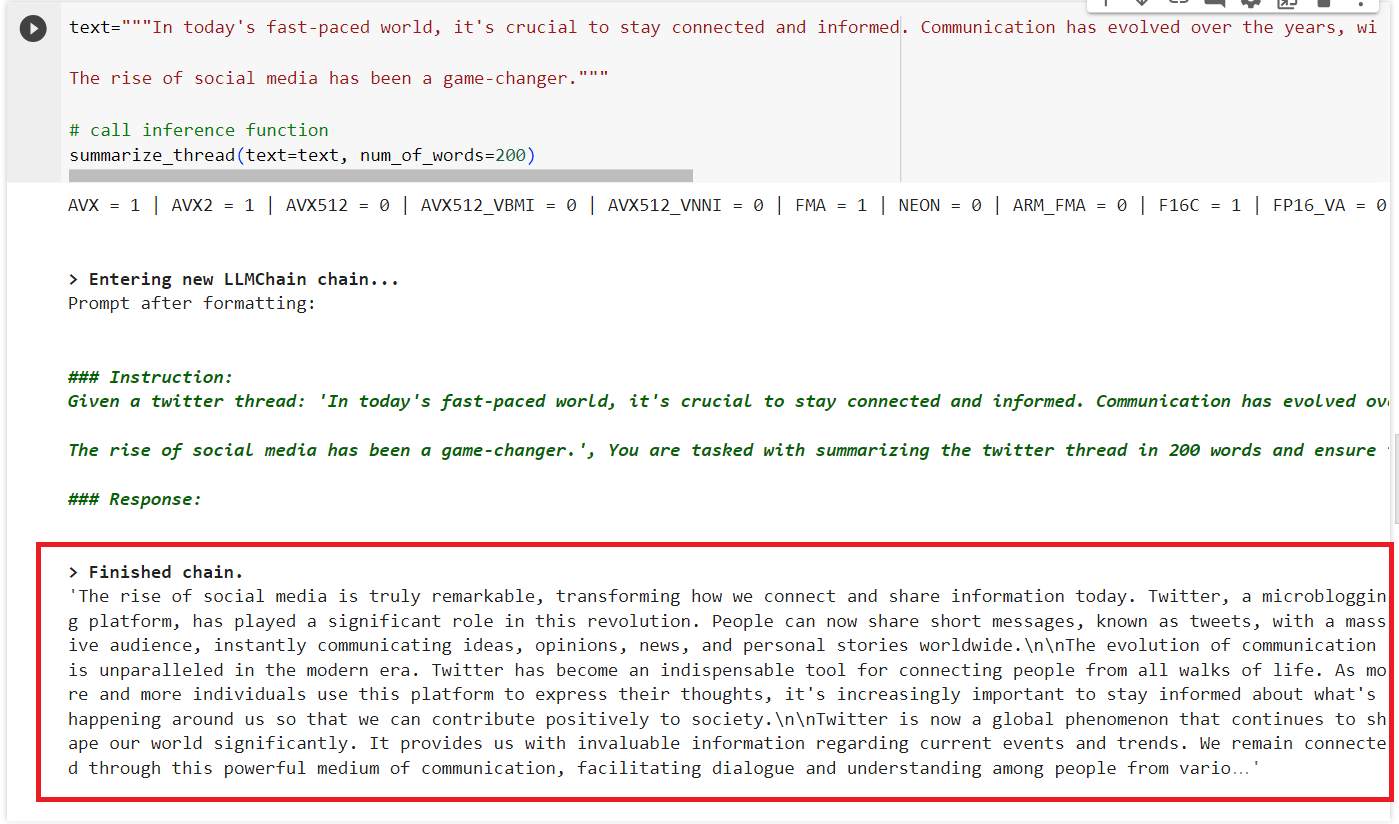
In this step, validate the function with a sample test case. Do this by running the following code:
In this test, you could consider the text “In today's fast-paced world, it's crucial to…” a Twitter thread, a user query. But it could also be any text you want to summarize. Switch the prompt templates if you prefer to change the application context.
If you run this example on Colab, returning the summary might take some time (~ 2 to 4 minutes). Herein lie the issues with running LLMs, especially if you do not put in the extra effort to optimize GPU usage (tuning the LlamaCpp model parameters).
Here is what the output of this function should look like:
Setting up Modelbit for deployment of your Llama-2 model
Now that we have set up our environment, you need to authenticate Modelbit to securely connect to your kernel so that only you and authorized users can access your files and metadata
👉 NOTE: If you don’t have a Modelbit account, sign up here—we offer a free plan you can use to run this demo.
Log into the "modelbit" service and create a development ("dev") or staging ("stage") branch for staging your deployment. Learn how to work with branches in the documentation.
If you cannot create a “dev” branch, you can use the default "main" branch for your deployment:
The command should return a link to authenticate your kernel. Click on the authentication link:
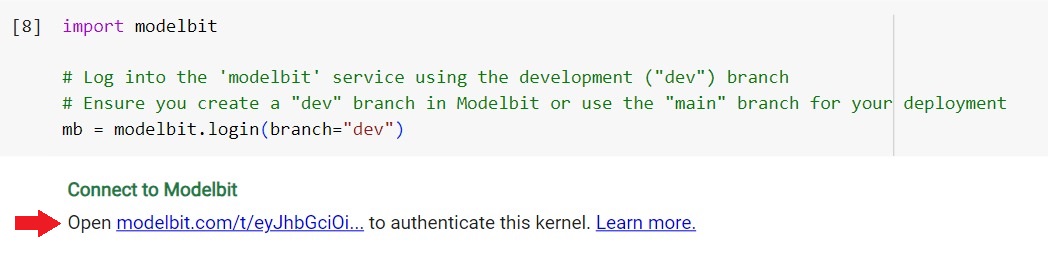
If the authentication is successful, you should see a similar screen:
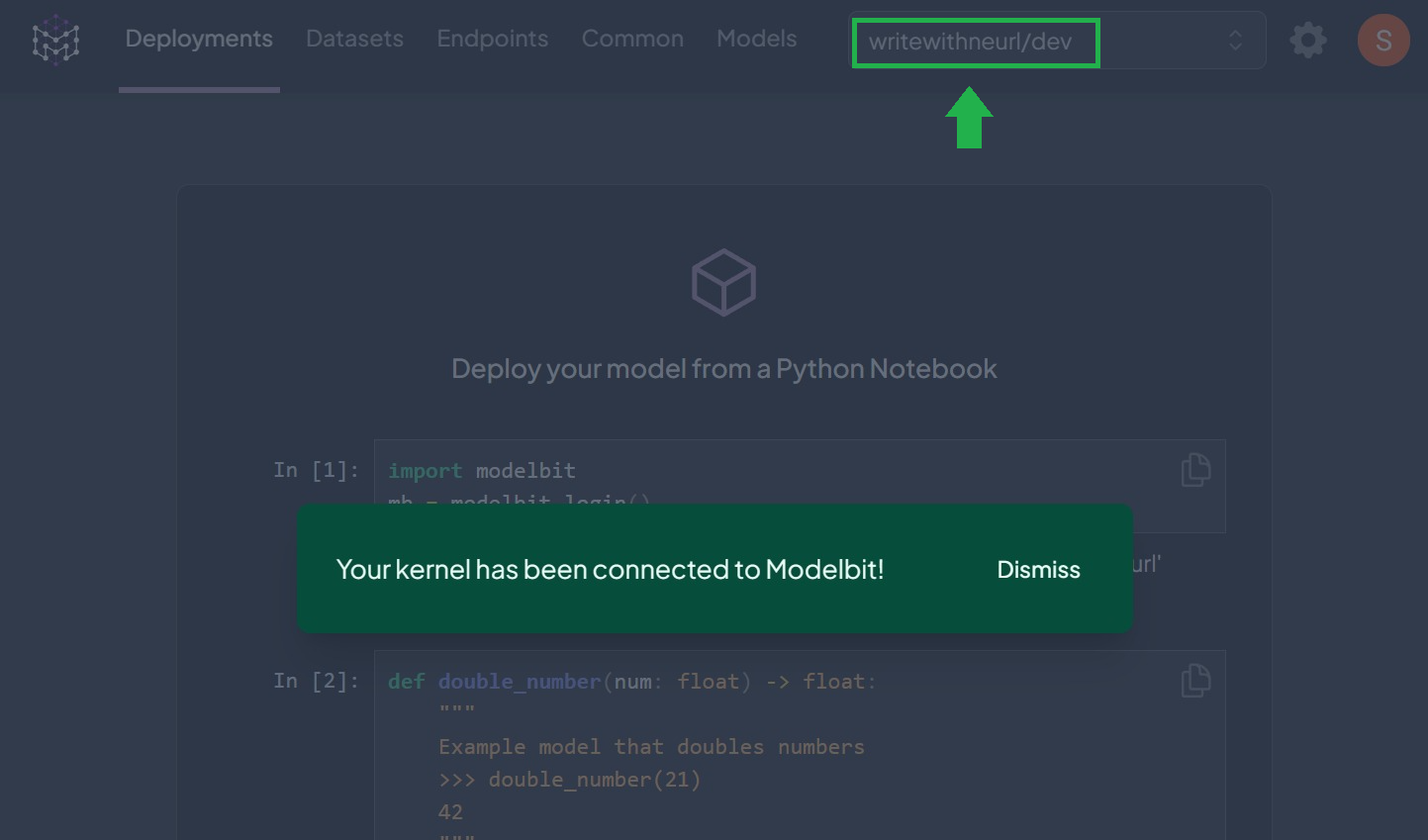
The kernel was authenticated to the right branch.
⚡ Deploy Inference Function to Production with “modelbit.deploy()”
We're now production-ready! Pass the model inference function ("summarize_thread") and the project dependencies to the "modelbit.deploy()" API. Modelbit identifies all dependencies, encompassing other Python functions and variables the inference function relies on.
Modelbit also detects the essential Python and system packages. Once this is done, it will set up a REST API for you!
This method deploys the “summarize_thread()” inference function, necessary extra files, and specific Python package versions. We explicitly require a GPU for the Llama 2-7B to use in the production environment.Internally, the API call pushes your source code to Modelbit, which builds a container with the model weights, Python functions, and necessary dependencies to replicate the notebook environment in production.
Deploy the inference function by running the code below:
The “extra_files” parameter stores the model embeddings (pre-trained weights) "llama-2-7b.Q4_0.gguf" you downloaded from Hugging Face earlier. If you want specific versions of your package to run in production, specify the versions so Modelbit can replicate them in production.
You should see a similar output from running that cell:
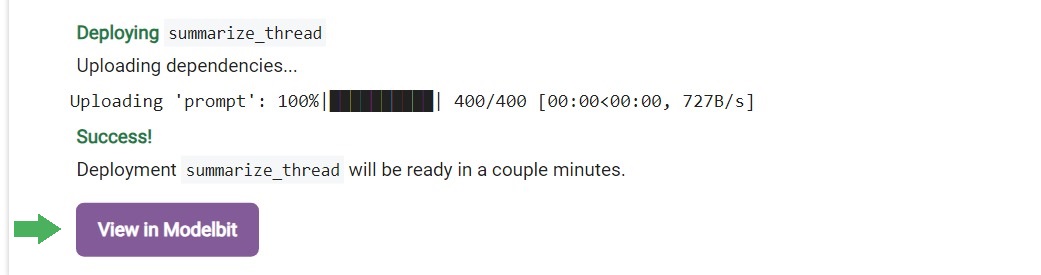
Click on “View in Modelbit” to see your Llama service being spun up in real-time:
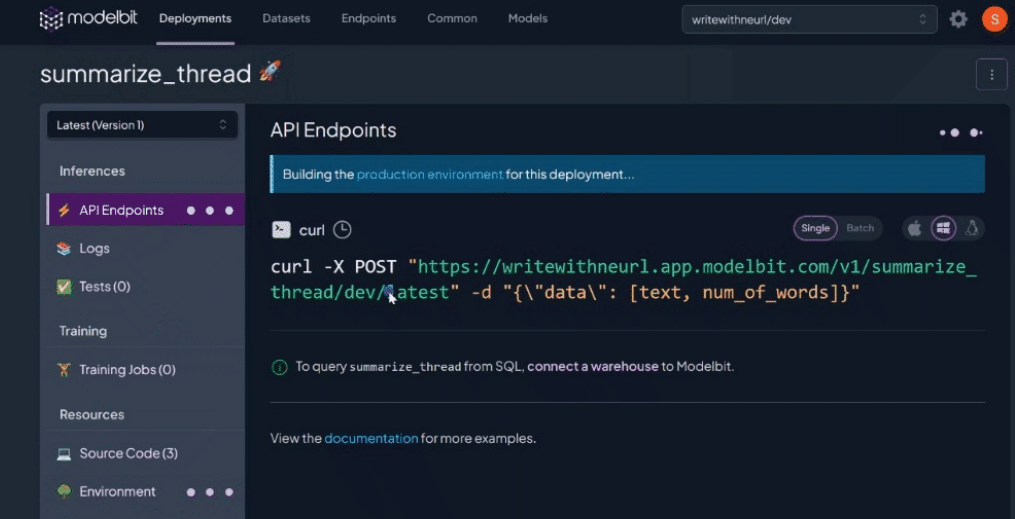
Once the build is complete, you should see the API endpoint where you can access your Llama 2-7B 🦙 deployment from and the source files “modelbit.deploy()” detected from your notebook environment:
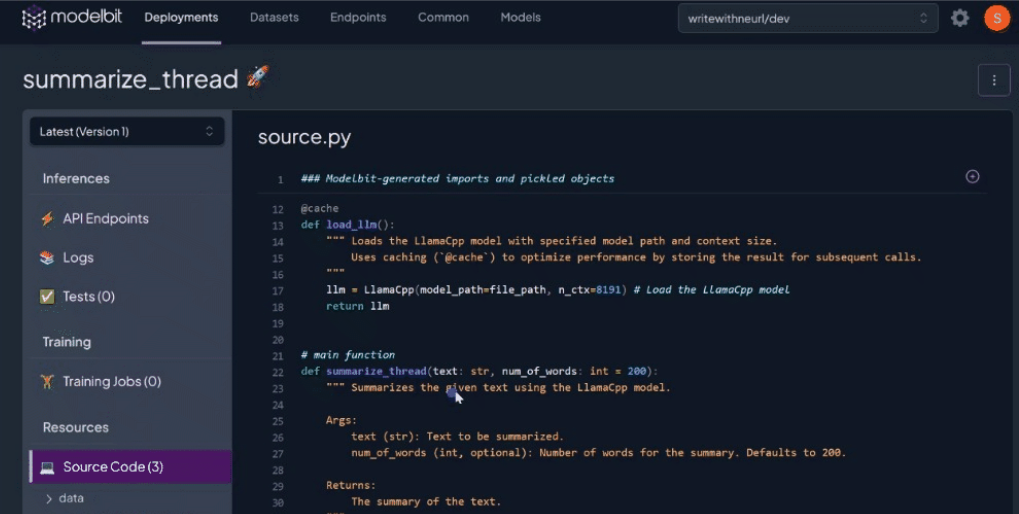
Ensure you copy your deployment endpoint from the Modelbit dashboard under “⚡API Endpoints”.
That’s it! You have a real-time endpoint ready to summarize a Twitter thread—Sorry Elon, it still goes by that!—from a user. Modelbit handles provisioning and auto-scales to the model’s needs in production.
Check the Colab Notebook for the entire code.
Test the Llama 2-7B 🦙 REST API Endpoint
To test the RESTful API endpoint, you could either call the API from the client programmatically with Python and the "requests" package or use the "cURL" requests package to send single or batch requests to the API. Here, you will use the requests.post() method to send a POST request to the API and format the response in JSON.
Define the client request data (X thread content) with the number of words to return for summary:
Test the endpoint:
Because it’s an LLM, the outputs are non-deterministic, so you should expect a different summary or even hallucinations in the API responses. Here’s an example output when we run that script:
Alternatively, you can test the endpoint on your terminal using the “cURL” command. See the Colab Notebook for instructions on how to use that format.
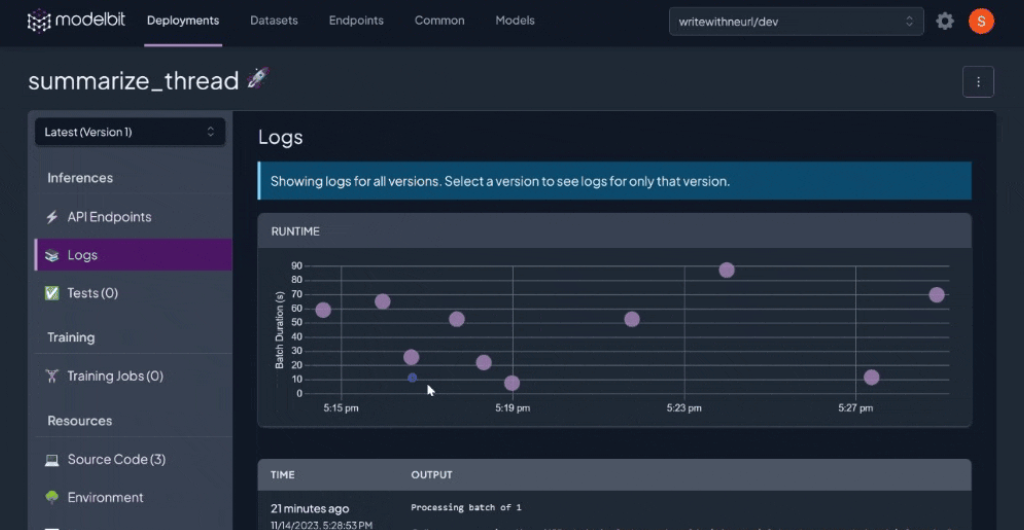
Monitoring Your LLaMA-2-7B Deployment
To see the usage and monitoring for your deployed model, navigate to the deployment on your Modelbit dashboard. Go to the “📚Logs” tab to view your usage analytics, log of requests and corresponding responses by the model, and system-related parameters.
Next Steps
Throughout this article, you have walked through a guide to deploying a pre-trained LLaMA-2-7B model as a RESTful API endpoint for a scalable text summarization service in production using Modelbit. The next step would be to integrate your deployment directly into the client application that parses a user’s Twitter threads and returns a response when it calls the API.
Before then, consider securing your endpoint! 🔐 Check out how in this documentation.
Until next time!
Want more tutorials for deploying ML models to production?
- Tutorial for Deploying Segment Anything Model to Production
- Tutorial for Deploying OpenAI's Whisper Model to Production
- Tutorial for Deploying Llama-2 to a REST API Endpoint
- Deploying DINOv2 for Image Classification with Modelbit
- Tutorial for Deploying a BERT Model to Production
- Tutorial for Deploying ResNet-50 to a REST API
- Tutorial for Deploying OWL-ViT to Production
- Tutorial for Deploying a Grounding DINO Model to Production
