.png)
ML Model Deployment Strategy: Lessons Learned from Decades of Software Development
Deploying ML models that will be used within a customer-facing product can be a somewhat nerve-racking endeavor. Sure, the model you’ve been developing has performed well in testing, but now that you’re ready to serve that model into production you’re realizing the stakes are much higher. The good news for machine learning teams is that there are battle-tested strategies for deploying ML into production that can de-risk the overall process, while also removing a lot of stress along the way.
As machine learning (ML) models become increasingly integrated into a wide range of applications, from fraud detection to object detection in images, it’s important to understand which best practices should be inherited based on the many lessons learned throughout decades of software development. This is especially true when the ML model you’re deploying is going to be integrated into the product at the core of your company’s value proposition. At Modelbit, we are working with our customers to build a modern ML deployment platform. Along the way, we have learned a lot from working various types of ML teams across different industries.
Among these best practices borrowed from software development, deciding upon and implementing the right deployment strategy is especially relevant when serving ML models into production. When we say strategy, we are not referring to the specific tactics used to replicate python environments into a container and building infrastructure to host them. Rather, when we talk about deployment strategy we are referring to the overall approach taken to ensure that new ML models are deployed in a manner that minimizes the risk of failure, while also maximizing speed and impact.
Much like software, and at the risk of stating the obvious, deploying ML models into production is challenging. At a minimum, machine learning teams need to consider the following when deploying a new model into production:
- The type of model: Some models, such as decision trees, are relatively easy to deploy. Others, such as deep learning computer vision models, can be more complex.
- The size of the model: Larger models can require more computing resources to deploy.
- The expected impact of the model: If the model is critical to the business, then it is important to have a more robust deployment strategy, because the risk of failure is that much greater.
- The agility requirements: How often does the model need to be updated? How quickly does it need to be deployed?
- The cost of hosting: How much will it cost to host the model? This is important even when considering for evaluation purposes.
Once you’ve taken all of these factors into consideration, deciding on the right strategy to roll out the new model into production is critical to ensuring that the risk of model failure is minimized and quickly addressable.
Do I Really Need To Have an ML Deployment Strategy?
The short answer is yes. However, how robust of a deployment strategy you should employ depends on the role your ML model is expected to play. Similar to shipping new products and features in software, it’s generally not a great idea to immediately ship a model into production if it hasn’t yet been tested in a production environment.
A well-defined ML deployment strategy can help to ensure that ML models are deployed in a reliable and efficient manner. It can also help to minimize the risk of problems, such as downtime or data breaches.
Here are some of the benefits of having an ML deployment strategy:
- Increased reliability: A well-defined deployment strategy can help to ensure that ML models are deployed correctly and that they are available to users when they need them. In other words, it can help keep your customers happy and reduce the risk of lost revenue.
- Improved efficiency: A good deployment strategy can help to streamline the overall deployment process and make it more efficient, saving time and money.
- More flexibility: The right deployment strategy can help to accommodate changes to the ML models or the environment in which they are deployed.
What to Consider When Picking an ML Model Deployment Strategy
There are many different ML deployment strategies available, with most, if not all, having their origins come from the world of DevOps. Ultimately, the best strategy for you will depend on some specific factors involved in your deployment.
Consider these when picking an ML model deployment strategy:
How fast do I need to deploy the new model?
If you need to deploy the new model quickly, then you may need to use a more aggressive deployment strategy. However, purely optimizing for speed can come with tradeoffs. The faster you direct all traffic towards a new model, the less time you have to evaluate its performance and impact.
How easy will it be to revert back to a previous model version?
This is critical. If the new model fails, what is the expected impact? If you’re updating or replacing an existing model in production, it is important to be able to revert back to a previous model version if something goes wrong.
What tooling and resources do I have available to me?
Not all machine learning platforms are created equal. Some teams rely on rigid, cost optimized systems that are heavily reliant on engineering. Typically, these sorts of machine learning platforms are harder to test and deploy new types of models with. On the other hand, some machine learning deployment platforms are more flexible and have different types of testing features baked into the product.
Types of ML Deployment Strategies and When to Use Them
We said earlier that most deployment strategies were developed over the years by teams building and deploying software. Below, we’ll outline some of the most common strategies, when they should be considered, and how they apply to deploying machine learning models into production:
ML Model Shadow Deployment
In shadow deployment, the new model is deployed alongside the old model. However, while the new model will start to log inferences, it won’t return them live. Instead, the new model’s inferences are monitored to see whether the model’s accuracy metrics hold up in the real world. If the new model performs well, then it can be switched over to production.
When to Use Shadow Deployment with ML Models
In terms of the speed at which you are actually updating or replacing a customer-facing model used in your product, this is the most conservative approach. If immediately replacing a model already running in production isn’t your biggest priority, then shadow deployments are a great strategy. We’re huge fans of shadow deployments for ML models because they allow you to evaluate a model’s performance against live traffic without any downside in the event that the new model fails or isn’t as good as the old model.
Shadow deployments in Modelbit’s product are referred to as request mirroring. We’ll explain how it works later on in this article.
ML Model Canary Deployment
With a canary deployment strategy the new model is deployed and begins to make return inferences against a subset of the live traffic. The new model is then monitored to see how it performs. If the new model performs well, then it can be gradually rolled out to more users.
When to Use Canary Deployment with ML Models
This is a good strategy to use if you want to minimize the potential impact of the new model failing. In other words, because you are only using the new model against a smaller portion of the overall live data traffic, it won’t negatively impact the majority of your end users. This is also a good strategy to use if you want to get feedback from users on the new model. Hopefully, that feedback won’t come in the form of a flurry of angry support tickets!
Unlike a Shadow Deployment, a Canary Deployment will let you observe the behavior of the users who actually receive the inferences from the new model instead. Maybe those new inferences cause them to buy more products or stay on your website longer. You wouldn't be able to observe those improvements with a shadow deployment. In that sense, the evaluation is more holistic than the more narrow technical evaluation of a shadow deployment.
Here are the steps involved in canary deployment:
- Deploy the new model to a small subset of users. This can be done by using a traffic split, where a small percentage of traffic is routed to the new model.
- Monitor the performance of the new model. This can be done by tracking metrics such as accuracy, latency, and error rate.
- If the new model performs well, gradually increase the percentage of traffic that is routed to the new model.
- If the new model does not perform well, roll back to the old model.
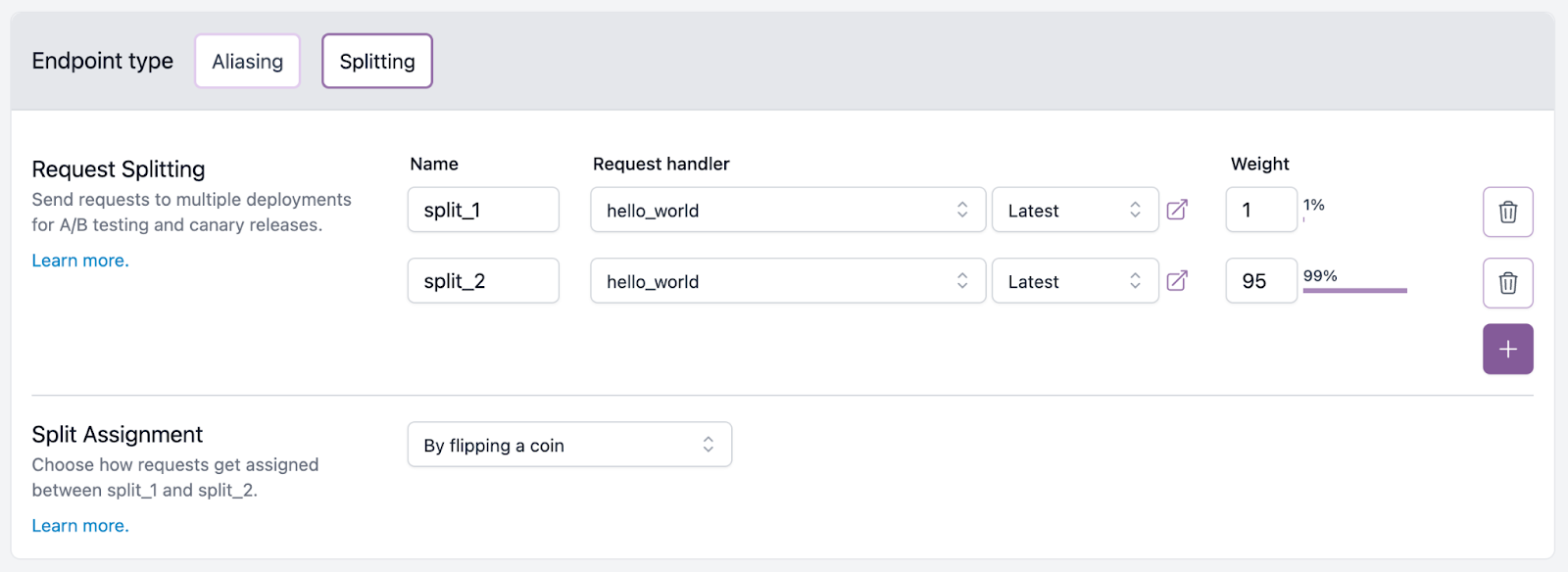
How easy it is for you to implement a canary deployment strategy will depend on a few factors, including the tooling you have available to you. In Modelbit, it’s as simple as assigning a request weight to different models that you’ve already deployed:
ML Model Blue/Green Deployment
In blue/green deployment, two identical production environments are created. The new model is deployed to the green environment, while the old model remains in production in the blue environment. Once the new model is deployed and tested, traffic is gradually switched from the blue environment to the green environment.
When to Use Blue/Green Deployment with ML Models
The need for something like a blue/green deployment strategy will depend on to what extent your company is building and maintaining custom production environments for model deployments.
If you’re using a tool like Modelbit, which handles deploying models into optimized production environments for you, then worrying about replicating production environments simply isn’t going to be relevant. With Modelbit, you can instead use features like Request Aliasing, which allow you to send traffic requests to different models over time, without having to change the REST URL.
However, if you are part of a team building custom production environments, then this could be a good strategy to use if you want to minimize things like the risk of downtime. It is also a good strategy to use if you want to be able to roll back to the old model if the new model fails. However, it is important to note that blue/green deployment can be more complex and expensive than other deployment strategies.
What We’ve Learned About ML Deployment from Our Customers
We on the Modelbit team consider ourselves lucky because we get to work with ML teams who are constantly looking for ways to incorporate the latest and most powerful model technologies being released by research teams such as Meta and Microsoft.
In fact, the pace at which our customers are looking to test and implement these newer model technologies has been a huge influence on our own product and have resulted in us releasing features to support the deployment strategies we laid out in this article.
While no two customer’s priorities and processes are the same, here is pretty typical approach we see our customers taking when getting ready to deploy new models into production:
Evaluating New Model Technologies
The latest and greatest model technologies can be very exciting and spark a lot of ideas of how they can be used to improve a product. However, they typically come with their own set of considerations and constraints before they can be fully implemented into a new product or feature.
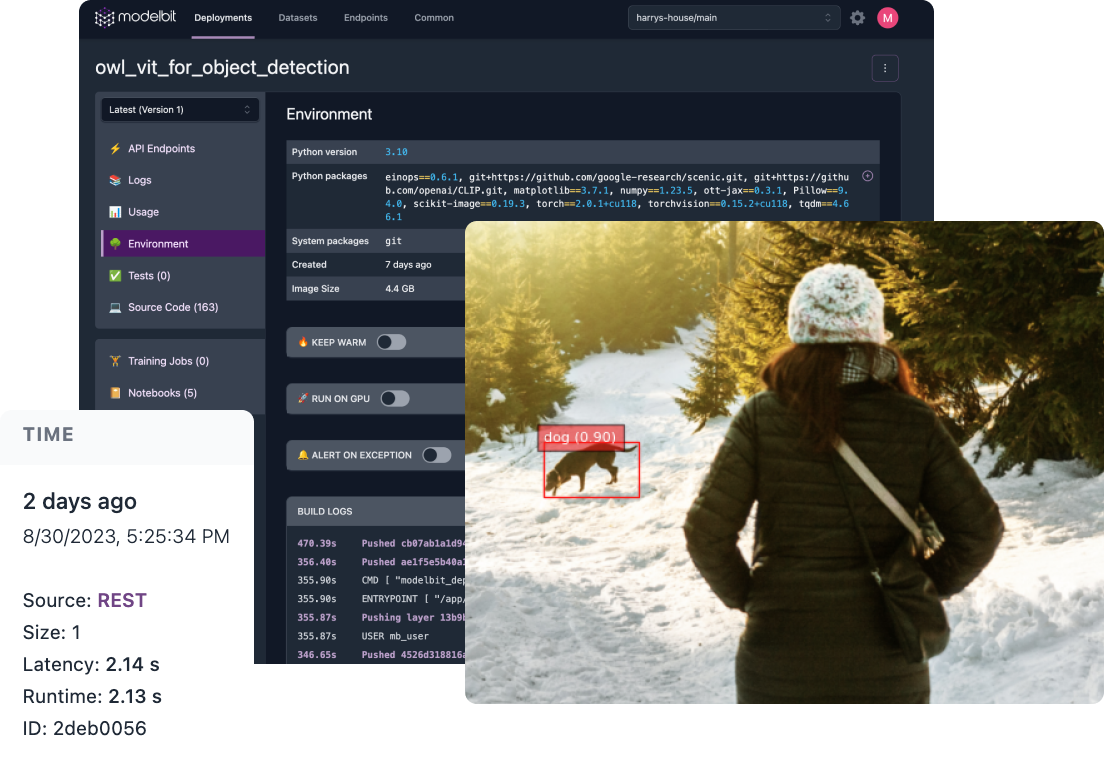
For this reason, we often see our customers train and deploy newer model technologies in a Jupyter notebook, or their favorite development environment, and then deploy those models into production by passing the inference function to "modelbit.deploy()". Modelbit automatically deploys the model, along with its dependencies, into a container hosted on our cloud, and generates a REST API.
The REST API can then be used to send requests to the model so that they can then start logging inferences and evaluating its performance.
If the idea is to replace an existing model already running in production, then our customers will typically have created an Endpoint in Modelbit which allows them to evaluate the model as a mirror (sometimes called a shadow deployment).
Making Incremental Improvements to Models in Production
While new model technologies are exciting, our customers are often making incremental improvements to the models they have running in production. Even if the changes are small, they still want to be able to evaluate the latest version of their model before fully replacing the old one.
For that reason, our customers will typically either use Modelbit’s Request Splitting (Canary A/B Testing) or Request Aliasing Shadow Deployment features when looking to quickly evaluate new versions of models.
Conclusion
At the end of the day, using a thoughtful and well planned deployment strategy is a tool in your arsenal to help you deploy ML models that make your product better, while minimizing all of the inherent risks associated with shipping new customer facing products. Every team has access to different tools, budget, and resources so there simply won’t be a cookie cutter approach that works best for everyone.